一、简述
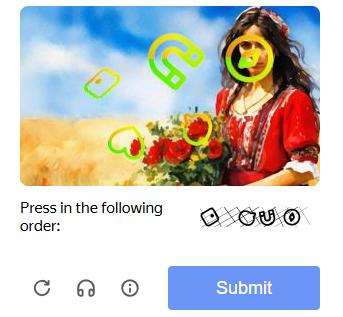
图标点选验证码,这里以各种图标通过顺序小图来判断与背景图中的图片是否相似,按照小图顺序逐个点击。
以某搜索引擎为例:aHR0cHM6Ly95YW5kZXguY29tLw==
验证码示例:
二、解决思路
1、训练图标检测模型,计算出图标坐标位置
包含背景图和小图
2、训练识别模型,计算出类型名称。
包含背景图和小图
3、通过识别出来的小图图标类型名称去跟识别出来的背景图图标类型名称对比,按照顺序依次获取正确点击图标的位置坐标结果。
涉及技术栈:yolov8、yolov11-cls
三、具体步骤
(一)检测模型训练
1、准备训练数据集
分别准备300-500张背景图和小图图片。
2、数据标注图标位置及训练
(1)数据标注及模型训练文件路径
这里标注图标位置,可以先通过X-AnyLabeling标注10-20张图片,然后训练一个最初版本的检测模型,然后再将模型导入到标注工具中实现批量标注。
X-AnyLabeling标注好后会在输出目录生成json文件,然后我们需要把json文件转为yolo训练所需要的txt文件类型,代码如下:
import json
def convert_json_to_yolo(json_path, yolo_path):
with open(json_path, 'r', encoding='utf-8') as f:
data = json.load(f)
img_w = data['imageWidth']
img_h = data['imageHeight']
yolo_lines = []
name = ['1'] #标签
name_class = {name[i]: i for i in range(len(name))}
for shape in data['shapes']:
if shape['shape_type'] != 'rectangle':
continue
num = name_class[shape['label']]
points = shape['points']
x1, y1 = points[0]
x2, y2 = points[2]
x_center = ((x1 + x2) / 2) / img_w
y_center = ((y1 + y2) / 2) / img_h
width = abs(x2 - x1) / img_w
height = abs(y2 - y1) / img_h
yolo_lines.append(f"{num} {x_center:.6f} {y_center:.6f} {width:.6f} {height:.6f}")
with open(yolo_path, 'w', encoding='utf-8') as f:
f.write('\n'.join(yolo_lines))
import os
import shutil
labels_dir_path = r'E:\advance_projects\点选验证码\图形点选\save_picture\valied36\labels_json'
input_dir_path = r'E:\advance_projects\点选验证码\图形点选\v2\images\valid\labels'
labels = os.listdir(labels_dir_path)
for i in labels:
if i.endswith("json"):
convert_json_to_yolo(f"{labels_dir_path}/"+i, f"{input_dir_path}/"+i.replace("json","txt"))现在我们需要创建一个项目文件夹作为根目录,如我这里命名为v1,然后在v1文件夹下创建一个images文件夹,其下分别创建train训练集文件夹和valid验证集文件夹。然后把图片和txt文件分别放到训练集和验证集文件夹下的images和lables文件夹下。具体如下所示:
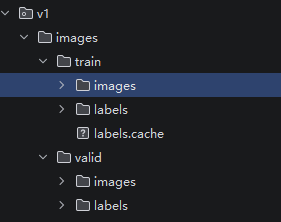
v1/images/train/images里放图片,labels里放txt文件。验证集一样。
(2)训练检测模型
1、配置yaml文件
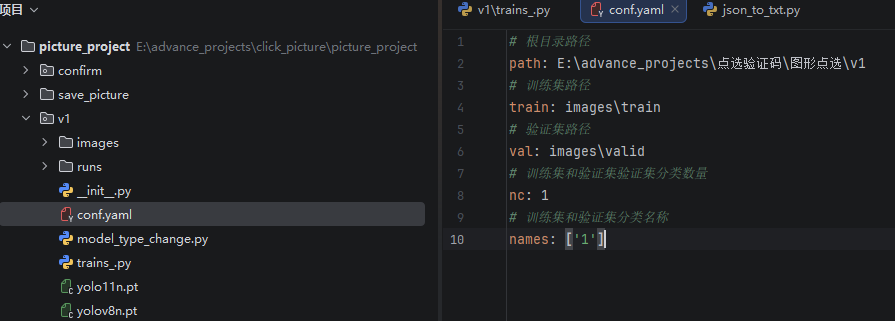
在v1目录下创建一个conf.yaml文件,具体参数如下:
path:分别填写根目录下的训练集和验证集目录路径即可。
nc:是训练集和验证集分类数量,根据标注的分类数量填写,如果只有一种,默认填1即可。
names:训练集和验证集分类名称。
2、下载基础模型
首先我们需要到yolo官网下载.pt基础训练模型,链接:Object Detection - Ultralytics YOLO Docs
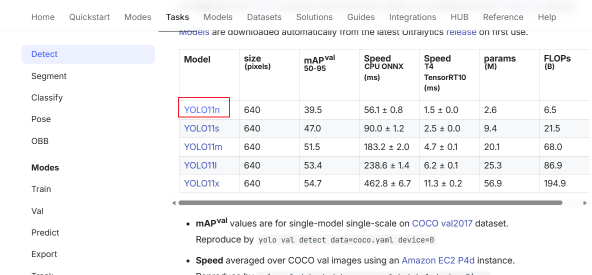
点击下载Model中最新的YOLO11n即可。将下载下来yolo11n.pt文件放到和v1目录下,和images同级。
3、训练检测模型
下载ultralytics包:pip install ultralytics
然后v1目录下创建trains.py文件,导入YOLO模块。将基础模型路径填上。开始训练即可。示例:
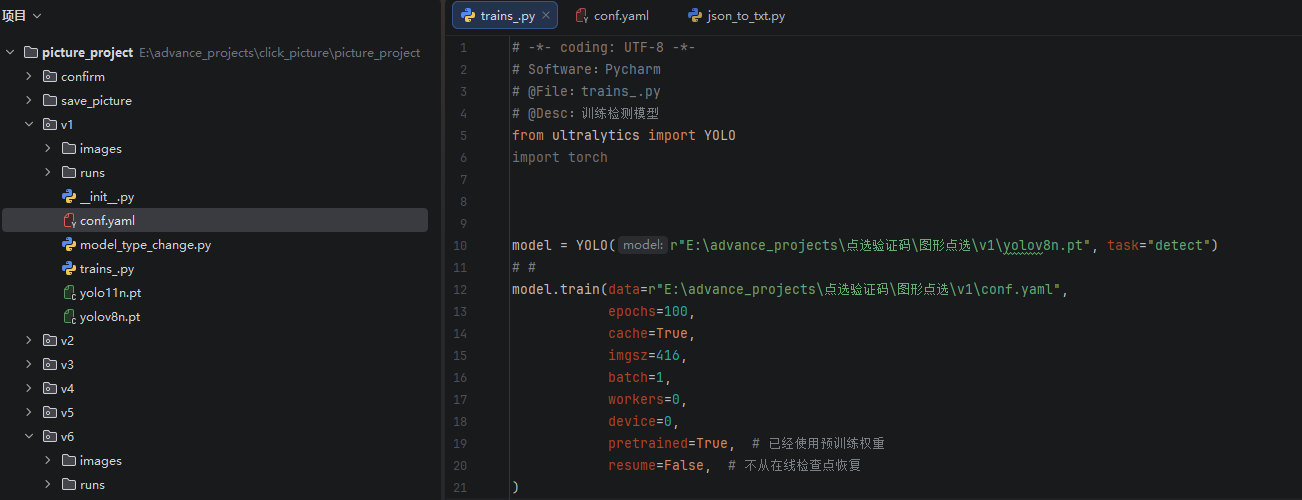
代码如下:
from ultralytics import YOLO
# import torch
model = YOLO(r"E:\advance_projects\点选验证码\图形点选\v1\yolov8n.pt", task="detect")
# #
model.train(data=r"E:\advance_projects\点选验证码\图形点选\v1\conf.yaml",
epochs=100,
cache=True,
imgsz=416,
batch=1,
workers=0,
device=0,
pretrained=True, # 已经使用预训练权重
resume=False, # 不从在线检查点恢复
)训练完成后,会在v1目录下生成一个runs文件夹,其路径下会产生一个权重文件,路径如下:v1/runs/detect/train/weights,weights文件夹下会生成一个best.pt文件,这个就是训练后检测模型文件。
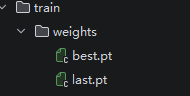
可以将其用来检测背景图坐标,具体代码示例如下:
具体示例如下:
若不想在调用训练好的检测模型生成runs文件夹,可加上这些参数:

将save和文本等文件保存参数设置为空。
3、pt模型转onnx模型
调用YOLO的导出功能即可。具体代码如下:
from ultralytics import YOLO
# 加载你训练好的模型
model = YOLO(r"E:\advance_projects\点选验证码\图形点选\v1\runs\detect\train\weights\best.pt")
# 导出为ONNX格式
model.export(format="onnx", imgsz=416)注意:imgsz需要与你训练时保持一致
执行之后会在best.pt相同目录下生成一个onnx模型,这样就可以自己调用了。如果想适配到X-AnyLabeling加载本地模型,自动识别相同类型验证码,则还需要在onnx模型相同目录下配置一个yaml文件。如下:
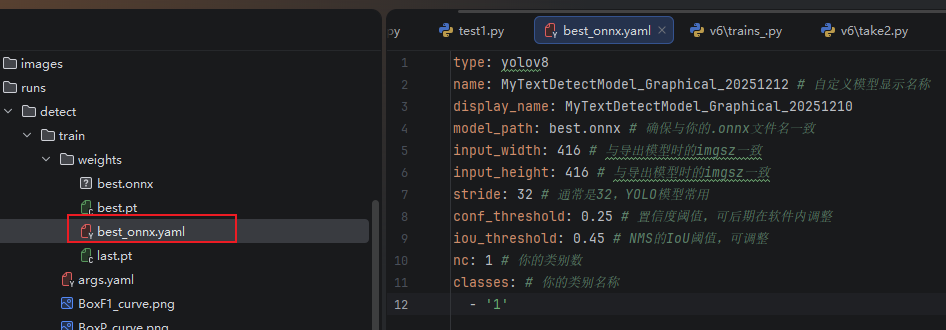
type:yolov8
name:为自定义模型显示名称。
display_name:显示的自定义模型名称
model_path:best.onnx (# 模型路径,需要与你的.onnx文件名一致)
input_width:416 (# 与导出模型时的imgsz一致)
input_height:416 (# 与导出模型时的imgsz一致)
stride:32(# 通常是32,YOLO模型常用)
conf_threshold:0.25(# 置信度阈值,可后期在软件内调整)
iou_threshold:0.45 (# NMS的IoU阈值,可调整)
nc:1(# 类别数量)
classes:
-'1'(# 你的类别名称)
这里只需要修改以上几个标注黑体的重点参数即可。
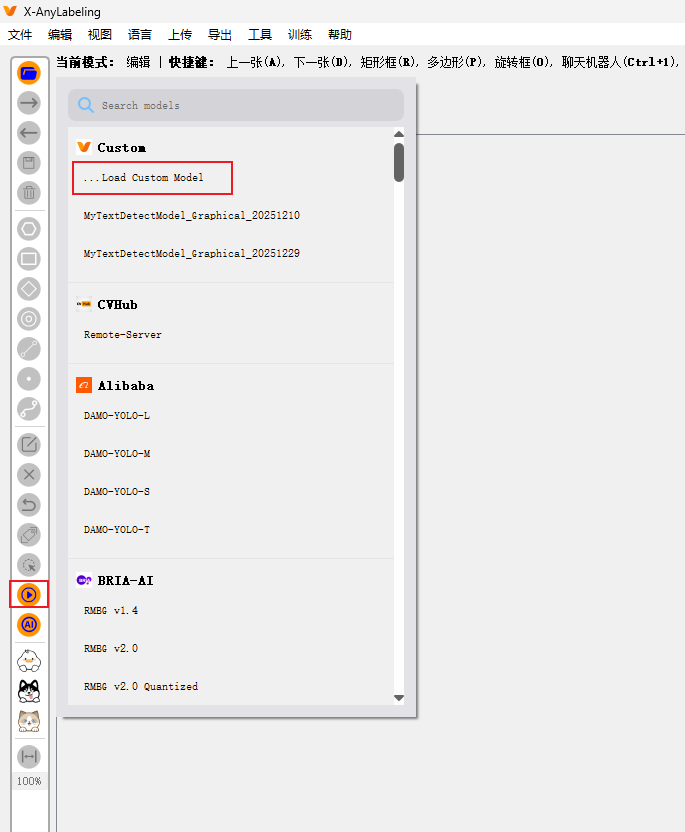
然后打开标注工具,点击模型图标,选择Custom中的load Custom Model加载本地模型,然后选择刚刚配置好的yaml文件。这样就可以自动标注或者批量标注了。
再按照以上方式训练灰色顺序小图的检测模型即可,也可以一块训练。以下的识别模型是放到一块训练的。
(二)识别模型训练
1、图标切割及分类。
首先,我们需要把图标切割单独保存到一个新的文件夹下,然后手动把切割下来的相同类型的小图放到相同的文件夹下。
注意:如果图标类型比较多,就每个图标类型拿5个左右,然后分好类,先训练一个识别率低的模型,然后再调用识别模型,读取全量切割的图标图片,根据识别结果放到指定文件夹。这样可以大大减少人工工作量。
如下所示:
每个图标类型准备10-15张左右即可。
然后把顺序小图同样切割放到相同目录下。
训练集和验证集的每个图标类型的文件夹的存放比例按照10:1即可。我们目前需要通过yolo的分类基础模型训练,所以images下的train和valid是不需要创建lables的,直接把分类好的文件放到训练集和验证集下面就好。
如何快速把训练集的每个背景图标和顺序灰度小图按照10:1的方式放到验证集文件呀里呢?由于这个验证码的图标类型大概有141种,如果每个都按照这种比例挑出来,同时还要注重背景图和小图的比例,工作量也不小。这里我写了一个检测脚本,根据路径读取识别图片的彩色背景图和灰色小图来进行推算比例,按照10:1的方式创建并移动到验证集文件夹下。代码如下:
import colorsys
import PIL.Image as Image
import os
import json
import shutil
# 获取图片主要颜色rgb值
def get_dominant_color(image):
max_score = 0.0001
dominant_color = None
for count, (r, g, b) in image.getcolors(image.size[0] * image.size[1]):
# 转为HSV标准
saturation = colorsys.rgb_to_hsv(r / 255.0, g / 255.0, b / 255.0)[1]
y = min(abs(r * 2104 + g * 4130 + b * 802 + 4096 + 131072) >> 13, 235)
y = (y - 16.0) / (235 - 16)
# 忽略高亮色
if y > 0.9:
continue
score = (saturation + 0.1) * count
if score > max_score:
max_score = score
dominant_color = (r, g, b)
return dominant_color
# 图片rgb值转为hsv
def rgb2hsv(r, g, b):
r, g, b = r / 255.0, g / 255.0, b / 255.0
mx = max(r, g, b)
mn = min(r, g, b)
m = mx - mn
if mx == mn:
h = 0
elif mx == r:
if g >= b:
h = ((g - b) / m) * 60
else:
h = ((g - b) / m) * 60 + 360
elif mx == g:
h = ((b - r) / m) * 60 + 120
elif mx == b:
h = ((r - g) / m) * 60 + 240
if mx == 0:
s = 0
else:
s = m / mx
v = mx
# 此时h,s,v值范围分别是0-360, 0-1, 0-1,在OpenCV中,H,S,V范围是0-180,0-255,0-255,加上下面代码转换:
H = h / 2
S = s * 255.0
V = v * 255.0
return H, S, V
# # 返回值是255 100 100的范围
# return h,s*100,v*100
def pan_duan_yan_se(h_0, s_0, v_0):
if 0 <= h_0 < 180 and 0 <= s_0 < 255 and 0 <= v_0 < 46:
return "黑色"
elif 0 <= h_0 < 180 and 0 <= s_0 < 43 and 46 <= v_0 < 220:
return "gray"
elif 0 <= h_0 < 180 and 0 <= s_0 < 30 and 221 <= v_0 < 255:
print("白色")
return "白色"
elif (0 <= h_0 < 10 or 156 <= h_0 < 180) and 43 <= s_0 < 255 and 46 <= v_0 < 255:
return "red"
elif 11 <= h_0 < 25 and 43 <= s_0 < 255 and 16 <= v_0 < 255:
return "yellow"
elif 26 <= h_0 < 34 and 43 <= s_0 < 255 and 46 <= v_0 < 255:
return "yellow"
elif 35 <= h_0 < 77 and 43 <= s_0 < 255 and 46 <= v_0 < 255:
return "green"
elif 78 <= h_0 < 99 and 43 <= s_0 < 255 and 46 <= v_0 < 255:
return "green"
elif 100 <= h_0 < 124 and 43 <= s_0 < 255 and 46 <= v_0 < 255:
return "blue"
elif 125 <= h_0 < 155 and 43 <= s_0 < 255 and 46 <= v_0 < 255:
return "blue"
else:
print("色调H超出范围,饱和度S,亮度V明度")
return "blue"
def get_color(image):
image = Image.open(image)
image = image.convert("RGB")
r, g, b = (
get_dominant_color(image)[0],
get_dominant_color(image)[1],
get_dominant_color(image)[2],
)
hsv_value = rgb2hsv(r, g, b)
h_0 = hsv_value[0]
s_0 = hsv_value[1]
v_0 = hsv_value[2]
return pan_duan_yan_se(h_0, s_0, v_0)
def not_block(train_dirs, train_path_data):
not_block_list = []
block_list = []
try:
for image_path in train_dirs:
image_path_all = train_path_data + "\\" + image_path
color_result = get_color(image_path_all)
if color_result == "黑色":
block_list.append(image_path)
else:
not_block_list.append(image_path)
return not_block_list, block_list
except Exception as e:
print(e)
def take_data(data_path, valid_path):
data_list = os.listdir(data_path)
print(data_list)
print(len(data_list))
for data in data_list:
train_path_data = data_path + "\\" + data
valid_path_data = valid_path + "\\" + data
if not os.path.exists(valid_path_data):
os.makedirs(valid_path_data)
train_dirs = os.listdir(train_path_data)
# 根据数据集的数量,取前2个数据集,分别放到train和valid中
# 判断总体非黑色数量
not_block_list, block_list = not_block(train_dirs, train_path_data)
not_block_num = round(len(not_block_list) * 0.2)
block_num = round(len(block_list) * 0.2)
for index, image_path in enumerate(not_block_list, 1):
if index > not_block_num:
break
train_dir_path = train_path_data + "\\" + image_path
valid_path_data_dir = valid_path_data + "\\" + image_path
shutil.move(train_dir_path, valid_path_data_dir)
for index, image_path in enumerate(block_list, 1):
if index > block_num:
break
train_dir_path = train_path_data + "\\" + image_path
valid_path_data_dir = valid_path_data + "\\" + image_path
shutil.move(train_dir_path, valid_path_data_dir)
# # 判断图片颜色
# for index, train_dir in enumerate(train_dirs, 1):
#
# train_dir_path = train_path_data + "\\" + train_dir
# valid_path_data_dir = valid_path_data + "\\" + train_dir
# shutil.move(train_dir_path, valid_path_data_dir)
# if index == 2:
# break
if __name__ == '__main__':
data_path = r"E:\advance_projects\click_picture\picture_project\v6\images\train"
valid_path = r"E:\advance_projects\click_picture\picture_project\v6\images\valid"
take_data(data_path, valid_path)
2、识别模型训练
(1)配置yaml文件
根据整理的图标分类文件,填写参数分类数量和分类名称
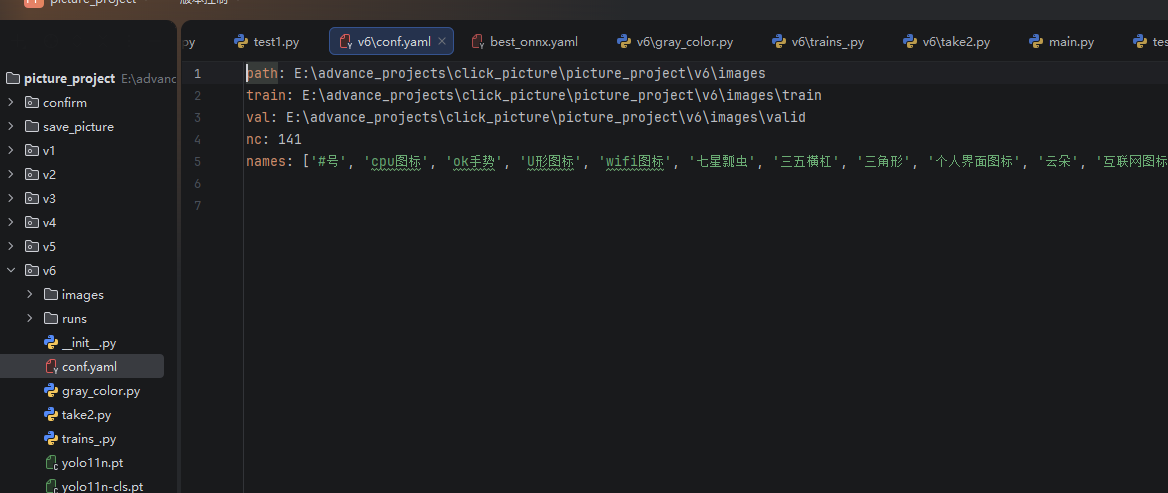
(2)下载yolo分类基础模型
由于我们识别是通过分类基础模型训练,所以我们需要到官网下载分类基础模型。地址:Image Classification - Ultralytics YOLO Docs

点击yolo11n-cls,下载yolo11n-cls.pt文件即可。
(3)训练识别模型
分别将下载好的分类基础模型和分类好的训练集和验证集图片路径填入即可。具体代码如下:
from ultralytics import YOLO
import torch
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
model = YOLO(r"E:\advance_projects\click_picture\picture_project\v6\yolo11n-cls.pt", )
if __name__ == '__main__':
results = model.train(data=r"E:\advance_projects\click_picture\picture_project\v6\images", epochs=100,
device=0,
imgsz=160)这里的plt.rcParams['font.sans-serif'] = ['SimHei'] 是因为用中文命名的分类名称,所以需要加特殊字体标注。
接下来进行训练,训练好后同样的会在weights文件夹下生成一个best.pt文件,这就是我们新训练好的图标识别模型。
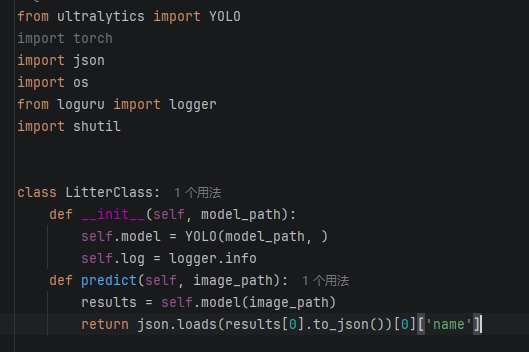
调用识别模型测试,代码如下:
import json
from ultralytics import YOLO
recognition_model_path = r"E:\advance_projects\click_picture\picture_project\v6\runs\classify\train\weights\best.pt"
# 本地测试图片路径
filepath = r'E:\advance_projects\click_picture\picture_project\v6\images\train\#号\2_e4038969-5b4d-478a-b582-dd551ebfb9a2.png'
recognition_model = YOLO(recognition_model_path)
results = recognition_model(filepath)
name = json.loads(results[0].to_json())[0]['name']
print(name)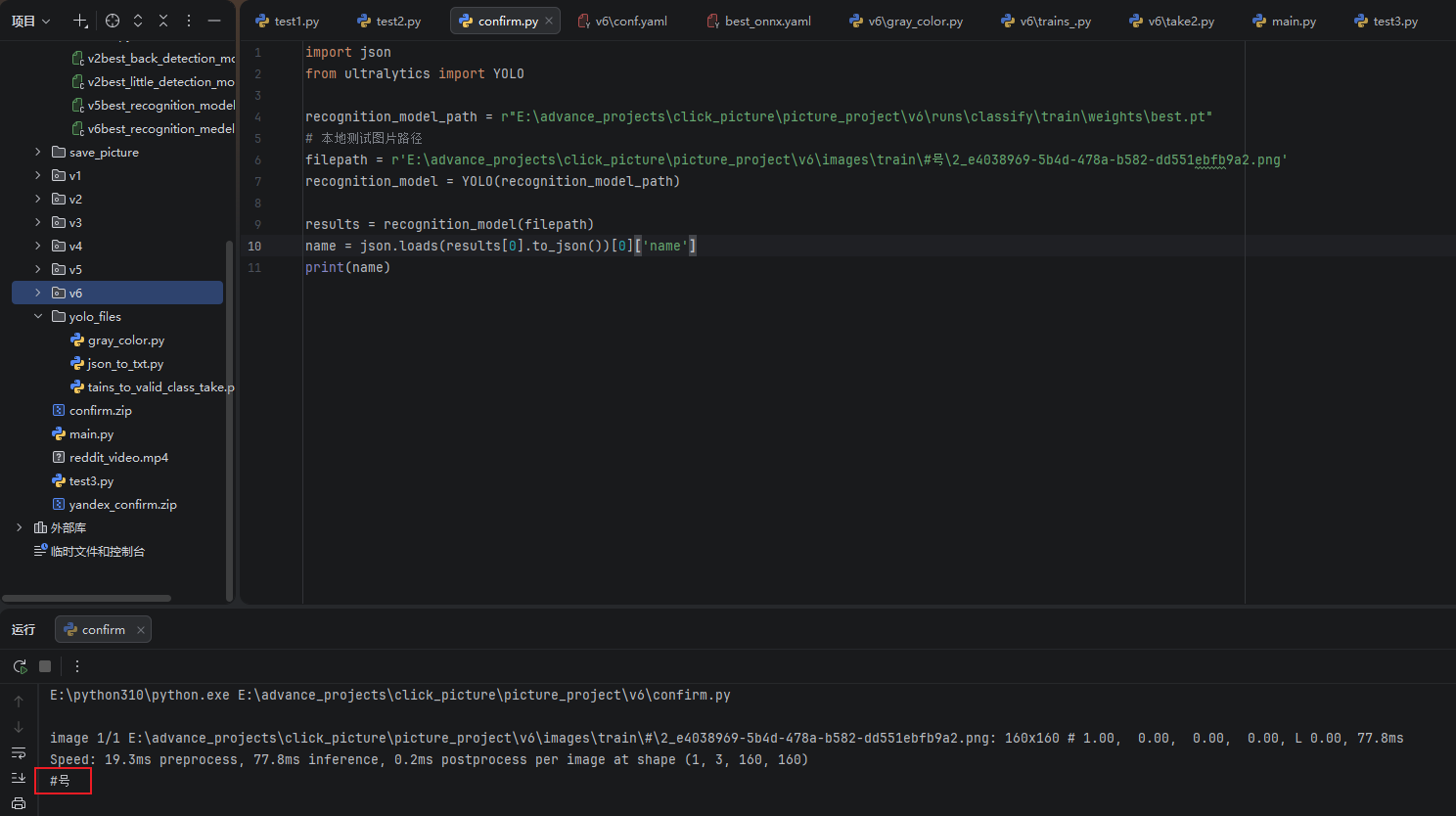
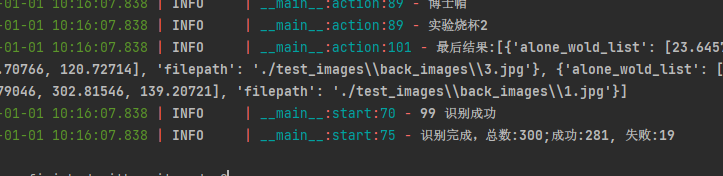
最后重新下载300张,调用检测模型识别坐标,根据坐标切割小图,通过识别模型识别图标类别,通过对比图标类型灰色顺序小图做比对获取最后的点选顺序坐标位置。发现识别成功率为93%。